
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- AWS
- 네트워크
- 코테준비
- 네트워크면접
- CICD
- 파이썬
- 네트워크기초
- 프로펙트부트캠프
- 프로펙트
- 백준
- 자료구조
- 제주코딩베이스캠프
- 리눅스기초
- 코딩테스트
- 터미널명령어
- argocd
- javascript
- 위니브
- 컴퓨터네트워크
- 제주ICT
- 네트워크핵심정리
- Python
- 개발자
- DevOps
- 리눅스
- 네트워크정리
- Linux
- 코테
- 더오름
- GitOps
- Today
- Total
hyei-devlog
[회고] goormEats 프로젝트 단계별 트러블 슈팅 과정: 절차적 배포에서 GitOps까지 본문
[회고] goormEats 프로젝트 단계별 트러블 슈팅 과정: 절차적 배포에서 GitOps까지
winter126 2025. 12. 23. 03:20"왜 배포 코드가 이렇게 복잡해야 하는가?"
2개월 간의 프로젝트를 진행하며 배포 파이프라인을 발전시켰다. 복잡한 배포 스크립트를 줄이고, 배포 시간을 12분에서 4분 30초로 단축했으며, UI 상으로 쉽게 롤백할 수 있는 시스템을 구축했다.
배달 서비스 플랫폼의 백엔드 일부 개발, 인프라 설계, CICD를 담당하며 5개의 마이크로서비스(User, Store, Order, Payment, Review)를 배포하는 과정에서 겪은 시행착오와 개선 과정을 기록했다.

1️⃣ 1차: 백엔드 서비스 개발 (2025.10.14 ~ 2025.10.30)
📍 목표
Java와 Spring Boot로 백엔드 서비스를 개발하고, 나는 Review Service를 담당하여 REST API와 JWT 토큰 기반 인증을 구현하는 것이 목표였다.
📍 문제
Java 개발이 처음이라 폴더 구조 설계부터 막막했다. 특히 헤더 검증 방식에서 JWT 토큰 검증으로 전환하는 과정에서 많은 시간이 소요되었다.
📍 해결 과정
생성형 AI에 DB ERD와 API 명세서를 제공하며 코드 초안을 빠르게 만들었고, 개발 경험이 많은 팀원에게 폴더 구조와 코드 리뷰를 요청해 피드백을 반영했다.
검증 단계에서는 Postman을 활용해 직접 API를 테스트했다. GET·POST·PUT·DELETE 각 메서드별로 엔드포인트를 구성하고, 요청마다 필요한 파라미터와 바디 값을 변수로 분리해 체계적으로 관리했다. 잘 작동이 되는지, 정상 케이스와 엣지 케이스를 나눠 입력값을 달리하며 응답을 검증했다. 이 과정에서 발견한 오류들을 하나씩 수정하며 Review Service 기능을 완성했다.
📍 1차 회고
기능은 완성했지만, 두 가지 큰 문제를 발견했다.
첫째, 기술적 이해의 부재였다. "어떤 어노테이션을 사용했냐"는 질문에 제대로 답하지 못했다. 동작하게 만드는 데만 집중한 나머지, 코드의 본질을 이해하지 못하고 있었다.
둘째, 배포 전략이 없었다. 개발은 끝났지만 이를 운영할 환경이 전혀 없었다. AWS 인프라도, CI/CD도 없는 상태였다.
2️⃣ 2차: AWS에 배포, Github Actions를 활용한 CICD 파이프라인 구성 (2025.10.31 ~ 2025.11.21)
📍목표
AWS ECS를 활용한 인프라 구축과 Github Actions 기반 CI/CD 파이프라인을 구축하고, 블루그린 배포 전략을 구현하는 것이었다.
📍기술 선택: ECS vs EKS
초기에는 EKS 도입을 검토했지만, 당시 상황과 맞지 않았다. 두 가지 이유였다.
첫째, 백엔드 서비스는 여러 개였지만 개발이 완전히 끝난 상태가 아니었다. 이벤트 기반 아키텍처로 고도화하는 과정이 남아 있었고, 배포해야 할 서비스의 전체 그림이 확정되지 않은 시점이었다. 우선 준비된 서비스부터 배포 환경을 갖추고 검증하는 것이 현실적인 순서였다.
둘째, Kubernetes는 Service·Ingress 등 익혀야 할 것들이 많았다. 아직 윤곽이 잡히지 않은 인프라를 위해 팀 전체가 학습 비용을 지불하는 것은 오버엔지니어링이었다.
팀원들과 회의 끝에 "학습 곡선이 가파른 EKS보다, 일단 ECS로 빠르게 배포 환경을 갖추자"는 결론을 내렸다. ECS는 AWS가 컨트롤 플레인을 완전히 관리해주기 때문에 컨테이너 실행에만 집중할 수 있었고, 그 목적에 맞는 선택이었다.
결과적으로 이 판단은 나쁘지 않았다. ECS를 직접 운영하면서 마이크로서비스가 늘어날수록 드러나는 한계를 직접 체감했고, 그 경험이 이후 EKS 전환의 근거가 됐다.
📍구현한 것들
1. Terraform으로 ECS 인프라 구축
인프라를 코드로 정의함으로써 환경을 언제든 동일하게 재현할 수 있었고, 변경 이력도 Git으로 관리할 수 있었다.
2. CI/CD 파이프라인 구성
각 서비스별 Dockerfile을 직접 작성하고, GitHub Actions → Docker Build → ECR Push → ECS Fargate 순서로 파이프라인을 구성했다. 코드가 git dev 브랜치에 병합되면 자동으로 컨테이너 이미지가 빌드되고 클러스터에 배포되는 흐름이다.
Github Actions → Docker Build → ECR Push → ECS Fargate

CI: Continuous Integration
CD: Continuous Delivery / Continuous Deployment
CI/CD: 코드 변경 → 자동 빌드/테스트 → 자동 배포까지 이어지는 자동화 파이프라인
3. 블루-그린 배포 구현
ALB에 두 개의 Target Group을 구성하고, 트래픽 전환 로직 전체를 GitHub Actions YAML에 직접 작성했다.
# 대략적인 배포 흐름 (실제 코드는 550줄)
1. 현재 어떤 서비스가 active한지 판단
2. 새 Target Group에 컨테이너 생성
3. 헬스체크 대기 (polling 방식으로 반복 확인)
4. ALB 리스너 규칙 변경하여 트래픽 전환
5. 기존 서비스 정리
6. 배포 후 모니터링
구현 자체는 동작했지만, 이 로직을 모두 GitHub Actions YAML 안에 담다 보니 파일이 550줄에 달했다. (이 복잡성이 이후 EKS + ArgoCD로 전환을 결심하게 된 직접적인 계기가 됐다.)
📍 CI 과정: 코드 검증
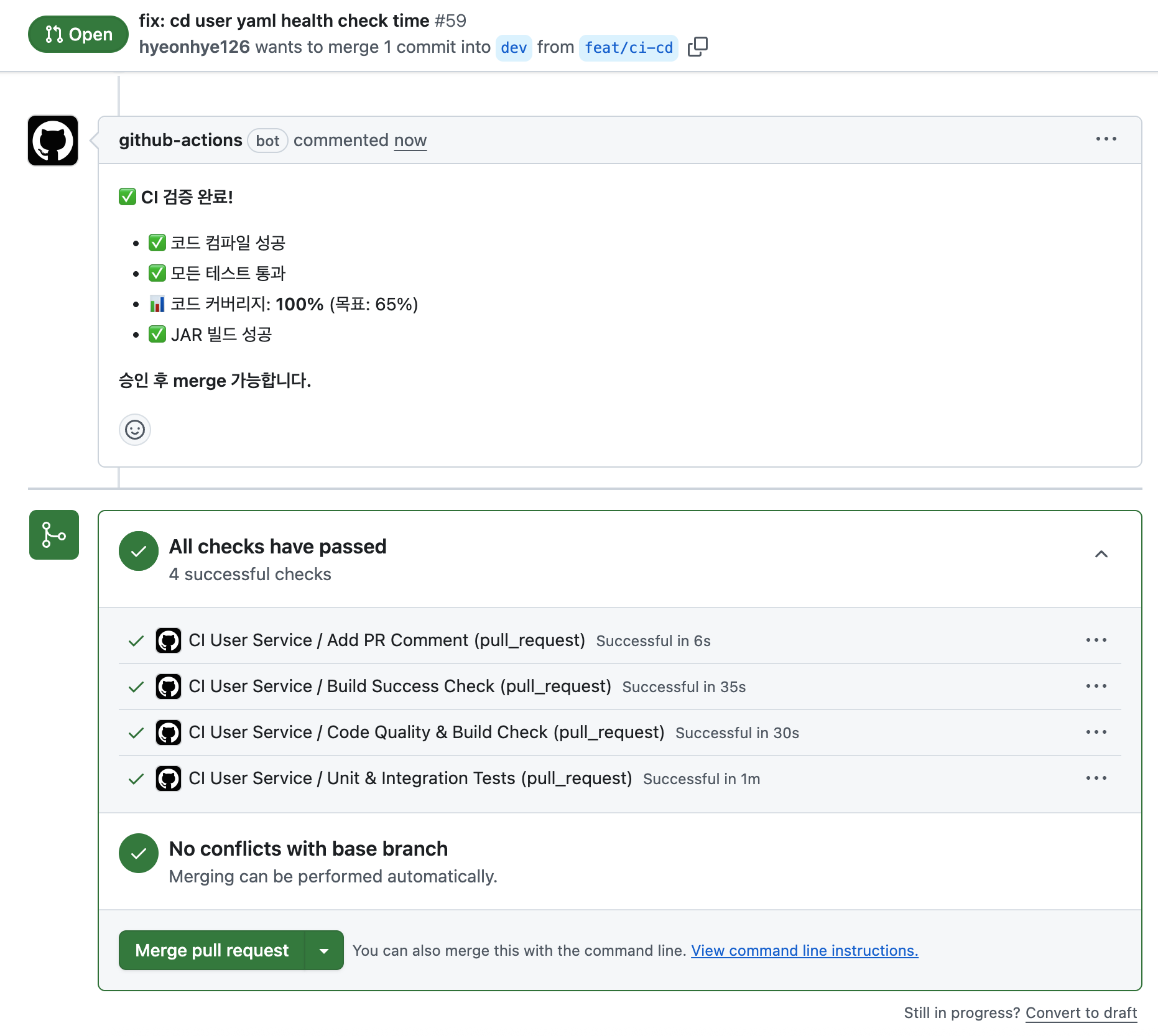
2차와 3차 프로젝트 모두 동일한 CI 파이프라인을 사용했다.
GitHub에 PR이 올라오면 GitHub Actions가 자동으로 4단계 검증을 수행한다.
STEP 1: 컴파일 검사 → JAVA 코드 문법 검증, 변수명 오류·타입 불일치 확인
STEP 2: 단위 테스트 → 테스트 코드 실행, 65% 커버리지 목표 (JaCoCo)
STEP 3: 빌드 검증 → JAR 파일 생성, 파일 존재 확인 (없으면 실패)
STEP 4: PR 코멘트 → ✅ 성공: "검증 완료" / ❌ 실패: "재시도 필요"
모든 체크가 통과되면 GitHub PR 화면에 "All checks have passed"가 표시되고, merge 버튼이 활성화된다.
CI 단계에서 문제가 발생하면 PR 코멘트로 즉시 피드백이 달려 어느 단계에서 실패했는지 바로 파악할 수 있었다.
📍 CD 과정: AWS ECS 배포
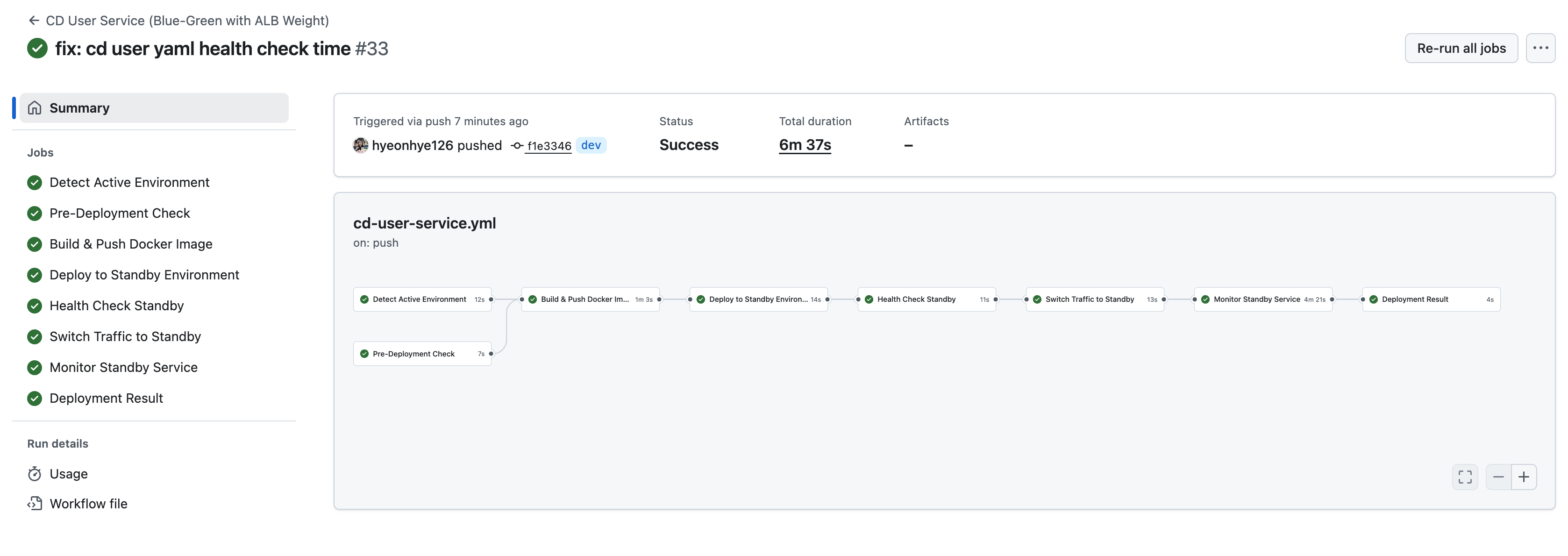
실제로 배포를 완료하는 데 약 12분이 걸렸다.
[전체 배포 타임라인 - 약 12분]
Stage 1: AWS 검증: 약 3초
Stage 2: 빌드 & ECR 푸시: 약 2분
Stage 3: Active 환경 감지: 약 5초
Stage 4: Standby 배포: 약 2분
Stage 5: 헬스 체크: 약 2~5분
├─ ECS Task 기동 대기: 최대 6분 (실제 1.5~2분)
│ → 10초마다 polling으로 Task 상태 확인
└─ ALB Health Check: 최대 5분 (실제 1.5~2분)
→ 10초 간격으로 Target Health 확인
Stage 6: 트래픽 전환: 약 5초
Stage 7: 배포 후 모니터링: 약 5분
→ 1분마다 5회 체크, AWS 콘솔에서 수동 확인
GitHub Actions 로그상으로는 약 6분 37초지만, Stage 7의 배포 후 추가 모니터링 시간을 포함하면 실제 배포 완료까지는 약 12분이 소요되었다.
📍 2차 회고
배포는 성공했지만, 몇 가지 문제를 발견했다.
문제1. 복잡한 YAML 파일
블루-그린 배포를 구현하기 위해 작성한 GitHub Actions CD workflow는 약 550줄에 달했다. (echo를 사용한 로그 출력 구문 포함)
# 실제 CD workflow의 구조...
jobs:
pre-deployment-check: # Stage 1: AWS 검증
steps: [...]
build-and-push: # Stage 2: 빌드 & ECR 푸시
steps: [...]
detect-active-env: # Stage 3: Active 환경 감지
steps:
- name: Detect which environment is active
run: |
# ALB 규칙 조회 및 가중치 확인
# 현재 어떤 환경이 100% 트래픽을 받고 있는지 판단
deploy-to-standby: # Stage 4: Standby 배포
steps:
- name: Deploy to Standby Service
run: |
# Task Definition 다운로드
# 이미지 변경
# ECS 서비스 업데이트
health-check-standby: # Stage 5: 헬스 체크
steps:
- name: Wait for standby tasks
run: |
for i in {1..36}; do
# 10초마다 Task 상태 확인 (최대 6분)
sleep 10
done
- name: Check ALB Target Health
run: |
for i in {1..30}; do
# 10초마다 Health 상태 확인 (최대 5분)
sleep 10
done
switch-traffic: # Stage 6: 트래픽 전환
steps:
- name: Update ALB Rule
run: |
# 가중치 변경하여 트래픽 전환
monitor-standby: # Stage 7: 모니터링
steps:
- name: Monitor for 5 minutes
run: |
for i in {1..5}; do
# 1분마다 상태 체크 (5분 강제 대기)
sleep 60
done
# ... 실제로는 더 많은 에러 처리, 로그 출력 등이 포함되어 550줄
절차적 배포 방식의 문제점은 다음과 같다. 가독성이 안 좋아서 배포 로직을 이해하려면 긴 스크립트를 다 읽어야 하고, 한 곳을 수정하면 연쇄적으로 다른 부분도 수정이 필요해 유지보수가 어렵다. 어디서 실패했는지 파악하기도 어렵고, Active/Standby 환경을 계속 추적하며 변수로 전달해야 하는 복잡한 상태 관리도 문제였다.
문제 2: 롤백 전략 부재
배포 후 문제가 생겼을 때 롤백하는 전략이 없었다.
문제 3: 긴 배포 시간
개발자는 배포 중 AWS ECS 콘솔 관리 화면을 바라보고 있어야 했다.
💡 2차 개발 요약
✅ 달성한 것
- Terraform을 활용한 ECS 인프라 코드화(IaC): 인프라를 코드로 관리하여 재현 가능하고 버전 관리 가능
- GitHub Actions 기반 완전 자동화된 CI/CD 파이프라인 구축: dev 브랜치 merge → 자동 배포
- 블루-그린 배포 전략 구현: ALB + Target Group 2개로 무중단 배포 실현
- 예외 처리 통일: 1차에서 지적받았던 예외 처리 방식 표준화
❌ 한계와 문제점
- 절차적 배포의 복잡도: CD YAML 파일이 550줄에 달하며 7단계의 순차적 로직으로 구성
- Active 환경 감지 → Standby 배포 → 헬스체크(polling) → 트래픽 전환 → 모니터링
- 한 단계 수정하면 연쇄적으로 다른 단계도 수정 필요
- 어디서 실패했는지 파악하기 어려운 구조
- 긴 배포 시간: 약 12분 소요 (GitHub Actions 6분 37초 + 추가 모니터링 약 5분)
- polling 방식의 반복 확인으로 대기 시간 길어짐
- 개발자가 AWS 콘솔 보며 대기해야 함
- 롤백 전략 부재: 문제 발생 시 AWS CLI로 수동 개입, 이전 버전 찾기도 어려움
- 배포 이력 관리 안 됨: 언제 무엇이 배포되었는지 추적 불가능
→ 다음 단계 과제
- 선언적 배포 방식으로 전환하여 복잡도 낮추기
- 배포 시간 단축
- Git 기반 배포 이력 관리 및 롤백 전략 수립
- 여러 마이크로서비스를 효율적으로 관리할 오케스트레이션 도구 필요
3️⃣ 3차: 인프라 환경 개선 - EKS, Github Actions, ArgoCD (2025.11.24 ~ 2025.12.10)
2차의 문제들을 해결하기 위해, 아키텍처를 재설계했다.
"왜 배포 코드가 이렇게 복잡해야 하는가?"
"원하는 최종 상태만 정의하면 되지 않을까?"
"배포 상태도 코드처럼 버전 관리할 수 있지 않을까?"

📍 기술 선택: EKS, Github Actions + ArgoCD
1. ECS → EKS
ECS의 한계
ECS는 AWS 생태계 안에서 컨테이너를 실행하는 데는 충분하지만, 마이크로서비스 수가 늘어날수록 한계가 드러진다. 서비스 간 의존성 관리, 리소스 스케줄링, 자가 복구 같은 기능을 ECS 자체적으로 구현하려면 추가적인 AWS 서비스를 조합해야 하고, 그만큼 운영 복잡도가 높아진다.
- 서비스 간 의존성 관리가 어려움
- 리소스 스케줄링과 자가 복구 기능을 구현하려면 추가 AWS 서비스 조합 필요
- 그만큼 운영 복잡도가 높아짐
EKS 도입 이유
여러 마이크로서비스를 하나의 플랫폼에서 일관되게 관리하기 위해 Kubernetes 기반의 EKS로 전환했다. Kubernetes는 Pod 단위의 세밀한 리소스 관리, 자동 스케일링, 자가 복구를 기본으로 제공하며, Deployment·Service·ConfigMap 등 모든 인프라 상태를 YAML로 선언적으로 정의할 수 있다.
- 일관된 관리: 여러 마이크로서비스를 하나의 플랫폼에서 통합 관리
- 세밀한 제어: Pod 단위의 리소스 관리, 자동 스케일링, 자가 복구를 기본 제공
- 선언적 정의: Deployment, Service, ConfigMap 등 모든 인프라 상태를 YAML로 선언
- 확장성: 서비스가 늘어나도 일관된 방식으로 배포/운영 가능
이를 통해 서비스가 늘어나도 일관된 방식으로 배포와 운영을 관리할 수 있는 확장성을 확보했다.
2. 단일 CI/CD → CI + CD(Delivery) + CD(Deploy) 3단계 분리
2차에서는 CI/CD가 하나의 파이프라인 안에 뭉쳐 있었다. 3차에서는 각 단계의 책임을 명확히 분리했다.
[CI] 코드 검증 → GitHub Actions: 컴파일·테스트·빌드·PR 코멘트 (2차와 동일)
[CD-Delivery] 이미지 준비 → GitHub Actions: Docker 빌드 + ECR 푸시 + GitOps Repo 업데이트
[CD-Deploy] 클러스터 반영 → ArgoCD: Git 변경 감지 → EKS 클러스터 자동 동기화
이 분리를 통해 "무엇을 배포할지는 Git이, 어떻게 반영할지는 ArgoCD가" 처리하는 선언적 배포 파이프라인을 구성했다.
3. GitHub Actions 단독 → GitHub Actions + ArgoCD
절차적 배포에서 선언적 배포로의 전환했다.
GitHub Actions 단독 배포의 한계
GitHub Actions만으로 배포를 처리하면 "코드를 실행해서 배포하는" 절차적 방식이 된다. 즉, 파이프라인이 실패하거나 누군가 클러스터를 직접 수정하면 Git에 정의된 상태와 실제 클러스터 상태가 달라져도 이를 감지하거나 되돌릴 방법이 없다.
- "코드를 실행해서 배포하는" 절차적 방식
- 파이프라인이 실패하거나 누군가 클러스터를 직접 수정하면 Git 상태와 실제 클러스터 상태가 달라짐
- 이를 감지하거나 되돌릴 방법이 없음
- 배포 이력 추적이 어려움
ArgoCD 도입 이유

ArgoCD는 Git 저장소를 단일 진실 공급원(Single Source of Truth)으로 삼아 클러스터 상태를 지속적으로 동기화하는 GitOps 컨트롤러다. Git에 선언된 상태와 실제 클러스터 상태의 차이를 실시간으로 감지하고 자동으로 조정하기 때문에, 누군가 클러스터를 임의로 변경해도 원하는 상태로 되돌아온다. GitHub Actions는 이미지 빌드와 Git 매니페스트 업데이트까지만 담당하고, 실제 클러스터 반영은 ArgoCD가 맡는 역할 분리를 통해 "무엇을 배포할지는 Git이, 어떻게 반영할지는 ArgoCD가" 처리하는 선언적 배포 파이프라인을 구성했다.
- GitOps 철학: Git을 배포 상태의 유일한 진실 공급원으로 사용
- 지속적 동기화: Git에 선언된 상태와 실제 클러스터 상태의 차이를 실시간으로 감지하고 자동으로 조정
- 자동 복구: 누군가 클러스터를 임의로 변경해도 Git에 정의된 상태로 되돌아옴
- 명확한 역할 분리:
- GitHub Actions: 이미지 빌드 + Git 매니페스트 업데이트
- ArgoCD: 클러스터 배포 및 동기화
# 기존: "어떻게" 배포할지 550줄로 작성
for i in {1..36}; do
check_health
if healthy; then break; fi
sleep 10
done
# 개선: "무엇을" 배포할지만 정의
spec:
replicas: 3
image: my-service:v2.0.0
readinessProbe:
httpGet:
path: /health
4. Deployment → Argo Rollouts
표준 Kubernetes Deployment의 한계
기본 Kubernetes Deployment는 Rolling Update 전략만 기본 지원한다. 블루그린 배포를 구현하려면 Deployment를 두 개 관리하면서 Service의 selector를 수동으로 전환하는 방식으로 우회해야 하는데, 이 경우 YAML 구성이 복잡해지고 배포 상태를 추적하거나 롤백하는 과정을 직접 핸들링해야 한다는 운영 부담이 생긴다.
- Deployment를 두 개 관리하면서 Service의 selector를 수동으로 전환하는 방식으로 우회
- YAML 구성이 복잡해지고 배포 상태를 추적하거나 롤백하는 과정을 직접 핸들링해야 하는 운영 부담
Argo Rollouts 도입 이유
Argo Rollouts는 블루그린·카나리 배포를 일급 객체로 지원하는 Kubernetes 전용 Progressive Delivery 컨트롤러다. Rollout 리소스 하나로 배포 전략, 트래픽 전환 시점, 자동 롤백 조건을 선언적으로 정의할 수 있어 Deployment를 두 벌 관리할 필요가 없다. 또한 Argo Rollouts Dashboard를 통해 현재 블루/그린 버전의 상태와 트래픽 전환 현황을 실시간으로 시각화할 수 있어 배포 안정성을 높일 수 있다.
결과적으로 "블루그린 배포를 안전하게, 그리고 운영 복잡도 없이 선언적으로 관리" 하기 위해 Argo Rollouts를 선택했다.
- Progressive Delivery 전용: 블루-그린, 카나리 배포를 일급 객체로 지원
- 선언적 정의: Rollout 리소스 하나로 배포 전략, 트래픽 전환 시점, 자동 롤백 조건 정의
- 단순화: Deployment를 두 벌 관리할 필요 없음
- 시각화: Argo Rollouts Dashboard를 통해 현재 블루/그린 버전의 상태와 트래픽 전환 현황을 실시간으로 시각화
- 안전한 배포: 자동 롤백 조건 설정 가능
apiVersion: argoproj.io/v1alpha1
kind: Rollout
spec:
strategy:
blueGreen:
activeService: my-service
previewService: my-service-preview
autoPromotionEnabled: false📍 GitOps Repository 구조 설계
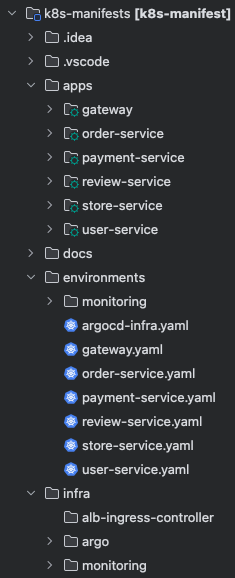
EKS와 ArgoCD 환경에서 MSA 서비스들을 체계적으로 관리하기 위해 k8s-manifests 레포지토리를 별도로 구성했다. 각 영역의 책임을 나눠서 변경 위험을 최소화하고 배포 흐름을 더 예측 가능하게 만들기 위한 구조다.
k8s-manifests/
├── apps/ # 서비스별 Helm Chart
│ ├── gateway/
│ ├── order-service/
│ ├── payment-service/
│ ├── review-service/
│ ├── store-service/
│ └── user-service/
├── environments/ # ArgoCD 배포 정의 (환경별 설정)
│ ├── monitoring/
│ ├── argocd-infra.yaml
│ ├── gateway.yaml
│ ├── order-service.yaml
│ ├── payment-service.yaml
│ ├── review-service.yaml
│ ├── store-service.yaml
│ └── user-service.yaml
├── infra/ # 클러스터 공용 리소스 (Monitoring 등)
│ ├── alb-ingress-controller/
│ ├── argo/
│ └── monitoring/
└── docs/ # 가이드 및 문서
각 디렉토리의 역할은 다음과 같다.
- apps/ 디렉토리는 서비스별 Helm Chart를 포함하며, 개별 MSA 서비스의 배포 템플릿과 서비스 단위 배포 설정을 독립적으로 관리한다.
- environments/ 디렉토리는 ArgoCD가 실제로 바라보는 배포 명세서로, apps/에 있는 Helm Chart를 특정 환경에 매핑하는 GitOps 배포 정의를 담는다.
- infra/ 디렉토리는 비즈니스 로직 외 클러스터 전체 공용 리소스(Argo Ingress, Prometheus, Grafana 등)를 관리한다.
📍 GitOps Repository Manifests 구성

각 서비스 Helm Chart 내부는 다음과 같이 구성했다. "모든 배포 관련 템플릿이 하나의 값을 참조하도록 일원화"하는 것이 핵심 원칙이었다. 배포에 사용되는 값이 여러 곳에서 따로 관리되면, 환경마다 불일치가 생기고 검증·롤백 시 기준을 잡기 어렵기 때문이다.
user-service/
├── templates/
│ ├── analysistemplate.yaml # 배포 성공 여부를 판단하는 메트릭 기준 (Prometheus 쿼리)
│ ├── configmap.yaml
│ ├── deployment.yaml
│ ├── external-secret.yaml
│ ├── hpa.yaml
│ ├── pdb.yaml
│ ├── rollout.yaml # Blue/Green 배포 전략 정의 (Active/Preview 트래픽 분리)
│ ├── service.yaml
│ ├── service-active.yaml # 프로덕션 트래픽을 받는 Service
│ ├── service-preview.yaml # 테스트용 Service
│ └── serviceaccount.yaml
├── Chart.yaml
└── values.yaml # 이미지 태그 변경 감지 및 배포 트리거 (Source of Truth)
📍 새로운 배포 플로우: CI → CD(Delivery) → CD(Deploy)
📌 CI(Integration): 코드 검증 (2차와 동일)
PR이 올라오면 GitHub Actions가 자동으로 4단계를 수행한다.
컴파일 검사 → 단위 테스트(JaCoCo 65% 커버리지) → 빌드 검증(JAR 파일 생성) → PR 코멘트(성공/실패 여부 자동 작성). 모든 체크가 통과되면 dev branch에 merge가 가능해진다.
📌 CD(Delivery): 이미지 빌드 & GitOps Repo 업데이트
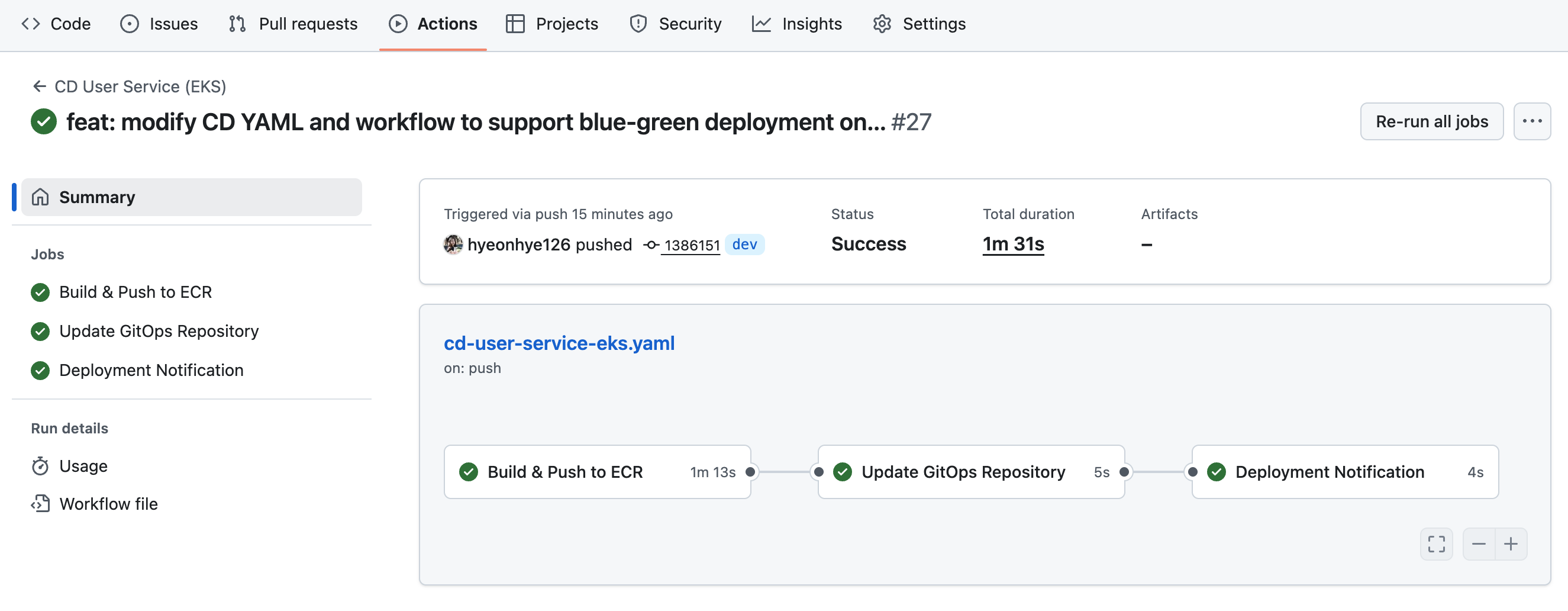
dev 브랜치에 merge가 완료되면 GitHub Actions CD 워크플로우가 3단계로 실행된다.
Stage 1: Build & Push to ECR (약 80초)
→ 소스코드를 Docker 이미지로 빌드하고 AWS ECR에 업로드
Stage 2: Update GitOps Repository (약 16초)
→ GitOps Repo의 Helm values.yaml을 새 이미지 태그로 업데이트
→ ArgoCD가 인식하는 유일한 변화는 Git에 기록된 상태 변화이므로,
빌드된 이미지 태그를 GitOps Repo에 반영하는 단계가 꼭 필요
Stage 3: Deployment Notification
→ 배포 성공/실패 여부를 콘솔에 출력GitHub Actions 실행 시간이 기존 6분 37초에서 1분 36초로 줄었다. CD 워크플로우가 완료된 이후에는 다른 작업을 할 수 있다.
📌 CD(Deployment): ArgoCD가 EKS 클러스터에 자동 반영
ArgoCD는 3분마다 Git 변경사항을 감지한다.
values.yaml의 이미지 태그 변경이 감지되면 Argo Rollouts가 Blue-Green 배포를 진행한다.
1. Green 환경 생성 → 새 버전 Pod 생성 및 준비
2. previewService 연결 → 자동으로 Green Pod에 연결
3. 헬스 체크 → 문제 없으면 수동 승인 대기
- startupProbe: 60초 대기 후 10초 간격으로 확인 (최대 6분, 실제 1~2분)
- readinessProbe: 10~30초 내 통과
4. 트래픽 전환 → Argo Rollouts를 통해 activeService를 Green으로 전환
→ ArgoCD UI에서 상태 확인 후 promote 명령어로 수동 전환
kubectl argo rollouts promote user-service -n default
5. Post 품질 검증 → AnalysisTemplate으로 HTTP 에러율(5% 미만), HTTP 응답 시간(P95) 검증
6. Blue 환경 삭제 → 문제 없으면 60초 대기 후 삭제
총 소요 시간: 약 4분 30초 (기존 12분 대비 62% 단축)
📌 GitOps 흐름 정리
1️⃣ CI — Continuous Integration
- 코드 merge
- 빌드
- 테스트
- Docker 이미지 생성
- 이미지 레지스트리(ECR 등)에 push
👉 애플리케이션 검증 + 아티팩트 생성 단계
2️⃣ CD (Delivery) — 배포 준비 단계
- 새 이미지 태그 기준으로
- GitOps 레포의 values.yaml 업데이트
- (Helm values 또는 k8s manifest 수정)
- Git에 commit & push
👉 “배포 가능 상태로 Git을 업데이트” 하는 단계
3️⃣ CD (Deployment) — 실제 클러스터 반영
- Argo CD가 Git 변경 감지
- Kubernetes 클러스터(EKS 등)에 sync
- 실제 배포 완료
👉 Deployment
구조: CI → Delivery → Deployment
GitOps 환경에서는 “Git이 변경되는 시점”과 “클러스터가 바뀌는 시점”이 분리되어 있기 때문에 Delivery / Deployment를 구분하는 게 더 명확하다.
GitOps 기반 CI/CD 파이프라인을 구축하여
CI 단계에서 이미지 빌드 및 검증을 수행하고,
CD(Delivery) 단계에서 Helm values를 업데이트하여 Git을 단일 소스로 유지하였으며,
Argo CD를 통해 CD(Deployment)를 자동화.
📍 개선 결과
1. 코드 복잡도 71% 감소
| 메트릭 | 기존(ECS) | 개선 (EKS + ArgoCD) | 개선률 |
| CD YAML 코드 라인 수 | 550줄 | 157줄 | 71% 감소 |
| 배포 로직 복잡도 | 절차적 (Imperative) | 선언적 (Declarative) | - |
(CD YAML 코드에는 로그 출력(echo)과 에러 처리 등이 포함되어 있다.)
2. 배포 시간 62% 단축
| 단계 | 기존 (ECS) | 개선 (EKS + GitOps) |
| CI 실행 | - | 1분 36초 |
| 빌드 & 푸시 | 2분 | 80초 |
| Task/Pod 기동 | 2분 (polling) | 1~2분 (자동) |
| Health Check | 2분 (polling) | 자동 처리 |
| 트래픽 전환 | 10초 | 1분 (검증 포함) |
| 배포 후 모니터링 | 5분 (수동 확인) | ArgoCD UI 확인 |
| 총 소요 시간 | 약 12분 | 약 4분 30초 |
GitHub Actions 실행 시간: 6분 37초 → 1분 36초 (76% 단축)
3. 블루-그린 배포 구현 비교
기존 (ECS + GitHub Actions): "어떻게 할지" 명령 (Imperative)
steps:
- name: Determine current active target group
run: |
CURRENT_TARGET=$(aws elbv2 describe-listeners ...)
if [ "$CURRENT_TARGET" == "blue" ]; then
NEW_TARGET="green"
else
NEW_TARGET="blue"
fi
- name: Wait for health check
run: |
for i in {1..30}; do
HEALTH=$(aws elbv2 describe-target-health ...)
if [ "$HEALTH" == "healthy" ]; then break; fi
sleep 10
done
- name: Monitor for 5 minutes
run: |
sleep 300
개선 (EKS + Argo Rollouts): "무엇을 원하는지" 선언 (Declarative)
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: review-service
spec:
replicas: 3
strategy:
blueGreen:
activeService: review-service
previewService: review-service-preview
autoPromotionEnabled: false
template:
spec:
containers:
- name: review-service
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
startupProbe:
httpGet:
path: /actuator/health
initialDelaySeconds: 60
periodSeconds: 10
readinessProbe:
httpGet:
path: /actuator/health
periodSeconds: 10
배포 과정:
- ArgoCD가 values.yaml의 이미지 태그 변경 감지
- Argo Rollouts가 새 버전(Green) Pod 생성
- Startup/Readiness Probe 자동 실행
- Argo Rollouts 대시보드에서 상태 확인
- Promote 콘솔 명령어 입력으로 트래픽 전환
kubectl argo rollouts promote user-service -n default
복잡한 로직이 사라지고, 안전한 수동 전환으로 배포 안정성을 확보했다.
Kubernetes가 지속적으로 Probe를 실행하기 때문에 스크립트로 강제 대기할 필요가 없어졌고, 로그를 직접 보지 않아도 ArgoCD UI에서 배포 상태를 실시간으로 파악할 수 있다.
트래픽 전환을 완전 자동화하지 않은 이유는, 이 단계가 서비스에 직접 영향을 주는 작업인 만큼 개발자가 상태를 눈으로 확인하고 최종 판단을 내리는 것이 안전하다고 봤기 때문이다. 기존에는 약 5분 동안 AWS 콘솔을 바라보며 대기해야 했다면, 개선 후에는 ArgoCD UI로 실시간 확인하고 준비되는 즉시 promote할 수 있어 실제 소요 시간이 약 1분으로 줄었다.
- ArgoCD UI에서 실시간 상태 확인
- 하트(♥) 아이콘: Pod의 Health 상태를 시각적으로 표시
- Green 환경의 모든 Pod가 Healthy인지 확인
- 로그를 직접 보지 않고도 배포 상태 파악 가능
- 왜 완전 자동화하지 않았나?
- 트래픽 전환은 서비스에 직접 영향을 주는 중요한 작업
- 개발자가 ArgoCD UI로 상태를 확인하고 최종 판단 후 수동으로 promote
- 안전성을 위해 자동화보다 수동 개입이 더 적합하다고 판단
차이점:
- 기존: 5분 동안 AWS 콘솔만 보며 수동 대기
- 개선: ArgoCD UI로 실시간 확인 → 준비되면 즉시 promote → 약 1분 소요
4. 배포 대기 방식 개선: polling → Kubernetes Probe
기존에는 ECS Task 상태를 10초마다 반복 확인하는 polling 방식을 사용했다. 최악의 경우 6분(36 × 10초)까지 대기해야 했다.
# 기존: 수동으로 상태를 반복 확인
for i in {1..36}; do
status=$(aws ecs describe-tasks ...)
if [ "$status" == "RUNNING" ]; then break; fi
sleep 10
doneKubernetes Probe로 전환하면서 이 대기 로직 자체가 사라졌다. 선언된 상태에 따라 Kubernetes가 직접 판단하기 때문에 개발자 개입이 불필요해졌고, 실제로는 1~2분 만에 통과했다.
# 개선: Kubernetes가 선언된 설정에 따라 자동으로 판단
startupProbe:
httpGet:
path: /actuator/health
initialDelaySeconds: 60
periodSeconds: 10
failureThreshold: 36
5. 개발자 경험(DX) 개선
기존 배포 경험:
[11:00] git push
[11:02] GitHub Actions 시작
[11:04] ECR 푸시 완료
[11:06] Task 생성 중... (터미널 응시)
[11:08] Health Check 중... (터미널 응시)
[11:10] 트래픽 전환 완료
[11:10] AWS ECS 콘솔 열어서 상태 확인... (수동 모니터링)
[11:15] 드디어 배포 완료!개발자는 AWS 콘솔을 바라보며 대기
개선된 배포 경험:
[11:00] git push
[11:01] GitHub Actions 완료 (다른 작업 가능!)
[11:02] ArgoCD Sync 버튼 클릭
[11:03] ArgoCD UI에서 배포 상태 확인
→ 하트(♥) 아이콘으로 Pod Health 확인
→ 새 버전(Green)이 모두 Healthy 상태임을 시각적으로 확인
[11:04] 터미널에서 promote 명령어 실행
→ kubectl argo rollouts promote user-service -n default
→ 개발자가 최종 판단 후 수동으로 트래픽 전환
[11:05] 배포 완료!
트래픽 전환은 서비스에 직접 영향을 주는 중요한 작업이기 때문에 완전 자동화하지 않았다. 개발자가 ArgoCD UI로 상태를 직접 확인하고 최종 판단 후 수동으로 promote하는 방식이 안전성 측면에서 더 적합하다고 판단했다.
📍자동 롤백 기준 설정
배포 후 자동으로 품질을 검증하고, 문제가 있으면 자동 롤백하도록 AnalysisTemplate을 작성했다.
apiVersion: argoproj.io/v1alpha1
kind: AnalysisTemplate
metadata:
name: review-service-analysis
spec:
metrics:
- name: error-rate
interval: 30s
count: 3
failureLimit: 1
successCondition: result < 0.05 # 에러율 5% 미만
provider:
prometheus:
address: http://prometheus:9090
query: |
rate(http_requests_total{status=~"5.."}[5m])
/
rate(http_requests_total[5m])
- name: latency-p95
interval: 30s
count: 3
failureLimit: 1
successCondition: result < 1.0 # P95 레이턴시 1초 미만
provider:
prometheus:
query: |
histogram_quantile(0.95,
rate(http_request_duration_seconds_bucket[5m])
)
의도한 동작은 30초마다 Prometheus 메트릭을 확인하고, 3번 연속 체크에서 1번이라도 기준을 초과하면 자동 롤백하는 것이었다. 다만 모니터링 담당 팀원의 Prometheus 메트릭 수집 구현이 미완성 상태여서 실제 동작을 검증하지 못했다. 배포 자동화만큼 모니터링 인프라도 함께 구축되어야 한다는 것을 배웠고, 다음 프로젝트에서는 초기부터 옵저버빌리티(Observability)를 함께 설계할 필요성을 인식했다.
의도한 동작:
- 30초마다 Prometheus 메트릭 확인
- 3번 연속 체크, 1번이라도 기준 초과 시 자동 롤백
배운 점:
- 모니터링 팀원의 Prometheus 메트릭 수집 구현 미완성으로, 제대로 된 동작을 체크하지 못했음
- 배포 자동화만큼 모니터링 인프라도 함께 구축되어야 함
- 다음 프로젝트에서는 초기부터 옵저버빌리티(Observability)를 함께 설계할 필요성을 인식
📍아쉬운 점: 카나리 배포, 세밀한 트래픽 제어 불가
현재 Argo Rollouts는 Pod 수에 따른 트래픽 분배만 가능하다.
# 현재: Pod 수로만 제어 가능
replicas: 3 # Blue
previewReplicas: 1 # Green
# 결과: 대략 75% vs 25% 분배
# 정확한 95% vs 5% 같은 제어는 불가능
만약 카나리 배포 방식을 적용한다고 가정하면, Argo Rollouts만을 사용하는 것은 카나리 배포의 본질에서 벗어난다고 생각했다.
진정한 카나리 배포(5% → 10% → 25% → 100% 점진적 증가)를 위해서는 Istio Service Mesh 도입이 필요하다. VirtualService와 DestinationRule을 조합하면 정확한 가중치 기반 트래픽 분배가 가능하고, 이는 다음 프로젝트의 목표 중 하나다.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: user-service
spec:
hosts:
- user-service
http:
- route:
- destination:
host: user-service
subset: stable
weight: 95
- destination:
host: user-service
subset: canary
weight: 5
---
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: user-service
spec:
host: user-service
subsets:
- name: stable
labels:
version: v1
- name: canary
labels:
version: v2💡 3차 개발 요약
✅ 달성한 것
- EKS 전환: 여러 마이크로서비스를 Kubernetes 기반으로 통합 관리
- Pod 단위 세밀한 리소스 관리, 자동 스케일링, 자가 복구 기본 제공
- 모든 인프라 상태를 YAML로 선언적 정의
- CI / CD(Delivery) / CD(Deploy) 3단계 명확한 역할 분리
- GitOps 아키텍처 구축: Git을 배포 상태의 단일 진실 공급원(Single Source of Truth)으로 사용
- k8s-manifests 레포지토리에서 모든 배포 상태 중앙 관리
- ArgoCD가 3분마다 Git 변경사항 감지하여 자동 동기화
- 선언적 배포 구현: 절차적 방식(550줄) → 선언적 방식(157줄)으로 71% 코드 감소
- "어떻게 할지" 명령 → "무엇을 원하는지" 선언
- 복잡한 트래픽 전환 로직이 사라지고 Argo Rollouts가 자동 처리
- Argo Rollouts 블루-그린 배포: 약 30줄의 선언적 manifest로 블루-그린 배포 완성
- ArgoCD UI로 시각적 모니터링
- kubectl argo rollouts promote 명령어로 안전한 수동 트래픽 전환
- 배포 시간 62% 단축: 12분 → 4분 30초
- Git 기반 롤백: Git revert만으로 최대 5분 내 이전 버전 자동 배포
- 모든 배포 이력이 Git commit history에 기록
❌ 한계와 시도했지만 미완성인 것
- 자동 롤백 기준 미완성: AnalysisTemplate 작성했으나 Prometheus 메트릭 수집 미완성으로 실제 테스트 못함
- 카나리 배포 세밀한 제어 불가: Pod 수 기반 트래픽 분배만 가능, 정밀한 제어를 위해선 Istio 필요
🔄 개선 사항 비교
- 개발자 경험: 12분 대기 → 2분 후 다른 작업 가능, UI로 시각적 확인
- 배포 방식: 절차적(7단계 순차 실행) → 선언적(원하는 상태만 정의)
- 롤백: AWS CLI 수동 개입 → Git revert 한 번
- 이력 관리: 없음 → Git commit history에 모두 기록
4️⃣ 마치며
2개월의 여정 요약
| 단계 | 핵심 문제 | 해결 방법 | 결과 |
| 1차 | Java 백엔드 개발 경험 부족 | 바이브 코딩 & 팀원 피드백 활용 | 기능 완성, but 기술적 이해 부족 |
| 2차 | 배포 파이프라인 부재 | ECS + GitHub Actions | 550줄 YAML, 12분 배포 |
| 3차 | 절차적 배포의 복잡도 | EKS + ArgoCD + GitOps | 157줄, 4분 30초 배포 |
💡 내가 얻은 인사이트
1. 절차적 vs 선언적
절차적 방식은 "어떻게 할지"를 단계별로 명령한다. 배포 스크립트가 길어질수록 중간 단계에서 실패했을 때 현재 시스템이 어떤 상태인지 파악하기 어렵고, 동일한 배포를 재현하려면 모든 단계가 동일한 순서로 성공해야 한다는 전제가 붙는다.
선언적 방식은 "최종적으로 어떤 상태여야 하는지"만 정의한다. 현재 상태가 어떻든 도구가 알아서 목표 상태로 수렴시키기 때문에, 사람이 중간 과정을 추적하거나 제어할 필요가 없다. Kubernetes와 ArgoCD를 사용하면서 배포의 복잡성이 줄어든 근본적인 이유가 여기에 있었다.
- 절차적: "어떻게 할지" 모든 단계를 명령 → 복잡하고 오류 발생 시 디버깅 어려움
- 선언적: "무엇을 원하는지" 최종 상태만 정의 → 단순하고 직관적
2. GitOps의 힘
Git을 인프라 상태의 단일 진실 공급원(Single Source of Truth)으로 사용하면, 클러스터에 어떤 변경이 생겨도 Git이 항상 기준점이 된다. 모든 변경사항이 커밋 히스토리에 남기 때문에 "언제, 누가, 무엇을 바꿨는지"가 자연스럽게 추적된다. 장애가 발생했을 때도 이전 커밋으로 되돌리는 것만으로 롤백이 완성된다.
- Git을 배포 상태의 단일 진실 공급원(Single Source of Truth)으로 사용
- 모든 변경사항이 Git history에 기록
3. 도구는 문제를 해결하기 위해 선택하는 것
처음부터 EKS를 선택했다면 오히려 독이 됐을 수도 있다. ECS로 운영하면서 마이크로서비스가 늘어날수록 관리 복잡도가 올라가는 것을 직접 체감했고, 그 경험이 "왜 Kubernetes가 필요한가"에 대한 답을 만들어줬다. 기술을 먼저 배우고 문제를 찾는 게 아니라, 문제를 먼저 경험하고 근본 원인을 파악한 뒤 적절한 도구를 선택하는 순서가 훨씬 단단한 이해로 이어진다는 것을 이번 프로젝트에서 확인했다. 좋은 도구는 도입 그 자체가 목적이 아니라, 구체적인 문제를 해결하는 수단일 때 비로소 가치를 발휘한다.
- 처음부터 EKS를 선택하지 않은 것이 오히려 좋았음
- ECS의 한계를 직접 경험하고, 왜 Kubernetes가 필요한지 체감
- 문제를 먼저 경험하고 → 근본 원인 파악 → 적절한 도구 선택
숫자로 보는 개선
- 배포 코드: 550줄 → 157줄 (71% 감소)
- 배포 시간: 12분 → 4분 30초 (62% 단축)
- GitHub Actions 실행: 6분 37초 → 1분 36초 (76% 단축)
- 롤백 시간: 수동 개입 필요 → Git revert 또는 Argo UI로 가능
다음 단계
기회가 된다면, 다음 프로젝트에서는 이런 것들을 시도해보려 한다. Istio Service Mesh를 도입해 VirtualService + DestinationRule로 정확한 가중치 기반 카나리 배포를 구현하고, 초기부터 Prometheus + Grafana를 구축해 자동 롤백 기준을 완성하며, 5% → 10% → 25% → 50% → 100% 점진적 Progressive Delivery를 실현하는 것이다.
배포는 끝이 아니라 시작.
더 나은 배포 경험, 더 안정적인 서비스를 위한 여정은 계속된다.
References
'🚀 groomEats Project' 카테고리의 다른 글
| [CICD] ArgoCD 배포 구조 비교 분석: Flat 방식에서 App of Apps 패턴으로 전환, 개별 관리에서 계층적 관리로 (0) | 2025.12.23 |
|---|---|
| [회고] 구름 PROPECT 프로펙트 클라우드 엔지니어링 과정: 0부터 서비스 배포까지, 8주간 만든 것들 (2) | 2025.12.23 |

